0x00 Preface
---
In penetration testing, critical code (such as shellcode) is often obfuscated to evade static detection and analysis.
I recently encountered an interesting sample that uses Braille Patterns to obfuscate strings, posing significant challenges for static analysis.
As shown in the figure below
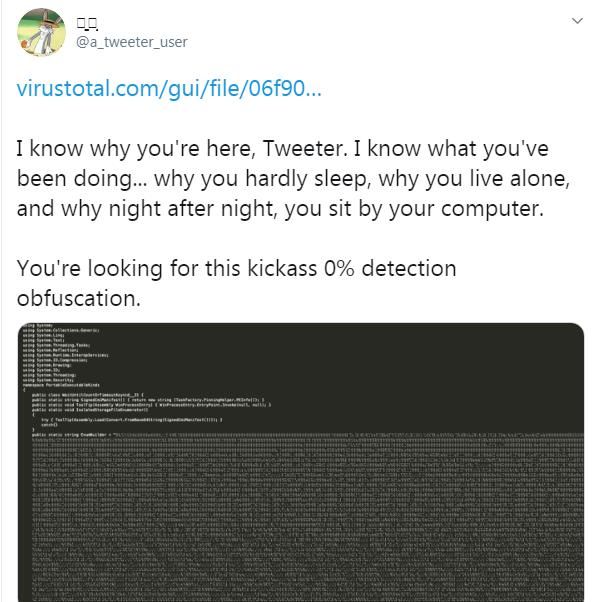
Sample address:
https://www.virustotal.com/gui/file/06f90a471f65de9f9805a9e907d365a04f4ebed1bf28b458397ad19afdb9ac00/detection
This article will introduce this method of obfuscating strings using Unicode encoding. It will cover implementing encoding and decoding for Braille Patterns through programs and share ideas for using other Unicode character tables for encoding and decoding.
0x01 Introduction
---
This article will cover the following:
- Implementation principles of the sample characters
- Encoding via program
- Decoding via program
- Approach to encoding and decoding using other Unicode character tables
0x02 Implementation principle of sample characters
---
Basic Knowledge 1: Unicode
Unicode is an encoding scheme developed to overcome the limitations of traditional character encoding methods. It assigns a uniform and unique binary code to each character in every language, meeting the requirements for cross-language and cross-platform text conversion and processing.
Simple understanding: Every character we see on a computer corresponds to a unique Unicode code.
Applying this to the sample mentioned above, although Braille Patterns are used to create difficulty for manual analysis, converting each character into its Unicode code can overcome this problem.
Basic Knowledge 2: Braille Patterns
These are specialized text symbols designed for blind people to read by touch and write.
Braille consists of 64 distinct patterns, meaning each character has 64 possible styles.
Braille Patterns occupy 256 positions in the Unicode table, meaning there are 256 Unicode codes corresponding to Braille Patterns.
To support more characters, the following method is used in the correspondence:
- Lowercase English letters correspond to single Unicode codes
- Arabic numerals correspond to two Unicode codes, with the first Unicode code fixed at U283C
- Uppercase English letters correspond to two Unicode codes, with the first Unicode code fixed at U2820
Note:
Lowercase English letters also correspond to two Unicode codes, with the first Unicode code fixed at U2830, but the first Unicode code is usually omitted
During the code obfuscation process, we can deviate from the above syntax to increase the difficulty of code analysis
For example, first encode the code in base64 (which consists of 64 characters), then randomly map it to the 256 zones of Braille Patterns
In summary, we can derive the implementation principle: convert the characters to be encrypted into Unicode codes, and then convert the Unicode codes into actual symbols
Therefore, decryption is also very simple: regardless of how complex the symbols are, first convert them into Unicode codes, then analyze them
To improve efficiency, the following sections introduce the methods for programmatically implementing encoding and decoding
For intuitive understanding, the program implementations all use Braille Grade 1 encoding, i.e., converting letter by letter, excluding abbreviations and other word-level transformations
0x03 Implementing Encoding via Program
---
For the implementation of encoding, simplicity and practicality are prioritized, so web-based encoding is chosen
Reference materials:
http://www.byronknoll.com/braille.html
This website supports Braille Grade 1 encoding
By viewing the source code, it can be found that http://www.byronknoll.com/braille.html implements Braille Grade 1 encoding through JavaScript scripts
Therefore, we only need to make simple modifications (fix some transcoding bugs, remove some features)
To check if there are bugs in the transcoding process, we need to know the Unicode and HTML codes corresponding to each Braille character. Reference materials available:
https://www.ziti163.com/uni/2800-28ff.shtml?id=83#
The correspondence between Unicode codes and English characters can be referenced from:
http://www.doc88.com/p-695153826363.html
The original code supports uppercase and lowercase letters, numbers, and some special symbols, but there are some bugs in the handling of special symbols, such as incorrect conversion for + and !
The modified code has been uploaded to GitHub and can be accessed directly for encoding at the following address:
https://an-open-source-project/tool/BrailleGenerator.html
Supports the following characters: 1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ),!/-.?;'$
Test as shown in the image below

Note:
My code only serves as a development template, so the conversion bugs for + and ! are not fixed, and + and = are not supported
0x04 Decoding via Program Implementation
---
To combine with exploitation methods (e.g., in-memory loading of PE files), C# is used here for implementation
For details on in-memory loading of PE files, refer to the previous article 'In-Memory Loading of PE Files via .NET'
The program implementation process is as follows:
1. Store the Braille characters obtained from BrailleGenerator.html in an array
2. Convert Braille characters into Unicode characters, noting that Arabic numerals and uppercase letters occupy two Unicode characters
3. Convert Unicode characters into actual characters through corresponding mappings
The code has been uploaded to GitHub at the following address:
An open-source project
Supports the following characters: 1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ),!/-.?;'$
Supports .NET 3.5 and newer versions
The compilation command is as follows:
C:\Windows\Microsoft.NET\Framework\v3.5\csc.exe BrailleToASCII.cs |
0x05 Approach for Encoding and Decoding Using Other Unicode Character Tables
---
1. Encoding
Convert the code into Unicode, generate new Unicode codes through custom mapping relationships, and finally convert them into corresponding symbols
Reference code:
An open-source project
2. Decoding
During exploitation, decrypt according to the encrypted mapping relationships
If analyzing samples with obfuscated code, set breakpoints before the code loading process to obtain the decoded content
0x06 Summary
---
This article uses Braille Patterns as an example to introduce the basic method of obfuscating strings using Unicode encoding. It demonstrates encoding and decoding of Braille Patterns through programs and briefly discusses the approach for encoding and decoding using other Unicode character tables.