Introduction
Entering 2026, AI Coding has shifted from "assisted completion" to "autonomous development." What truly transforms productivity is not that a single Agent writes code faster, but that you canLaunch multiple Agents simultaneously, letting them advance different tasks for you in parallel.
It's worth noting that what can be parallelized goes far beyond just writing code. As Agents can do more and more—researching, data analysis, writing documents, running tests, replying to emails, designing—almost all mental work that can be broken into independent subtasks has the potential for parallelization. This article only focuses ondevelopmentthis most mature scenario; but if you are doing other work, the ideas here can be transferred for consideration.
Back to development. The core question this article aims to answer is:How to have multiple AI Agents develop in parallel while ensuring output quality does not collapse?
To answer this question, we first need to understand:What is blocking parallelism?
Three Main Bottlenecks
TL;DR: What really limits AI development efficiency is not that AI writes slowly, but three links that require deep human involvement—they turn humans into single points of bottleneck, no matter how many Agents there are.
Bottleneck 1: How to clearly convey requirements to the Agent? The ideas in your mind are vague, implicit, and full of context, while the Agent needs clear, executable instructions. The gap in between often needs to be filled through repeated communication.
Bottleneck 2: How to ensure that the code written by the Agent is functionally correct? The code generated by the Agent looks plausible, but when actually run, it may have bugs everywhere. In the past, we relied on humans to review every line of code, find issues, provide feedback, and modify, repeating this process.
Bottleneck 3: How to ensure code maintainability? Code written by one Agent might run at the moment, but without reasonable architectural design and engineering standards, as the project progresses, the codebase quickly becomes a mess—chaotic structure, unclear responsibilities, changing one place breaks three.
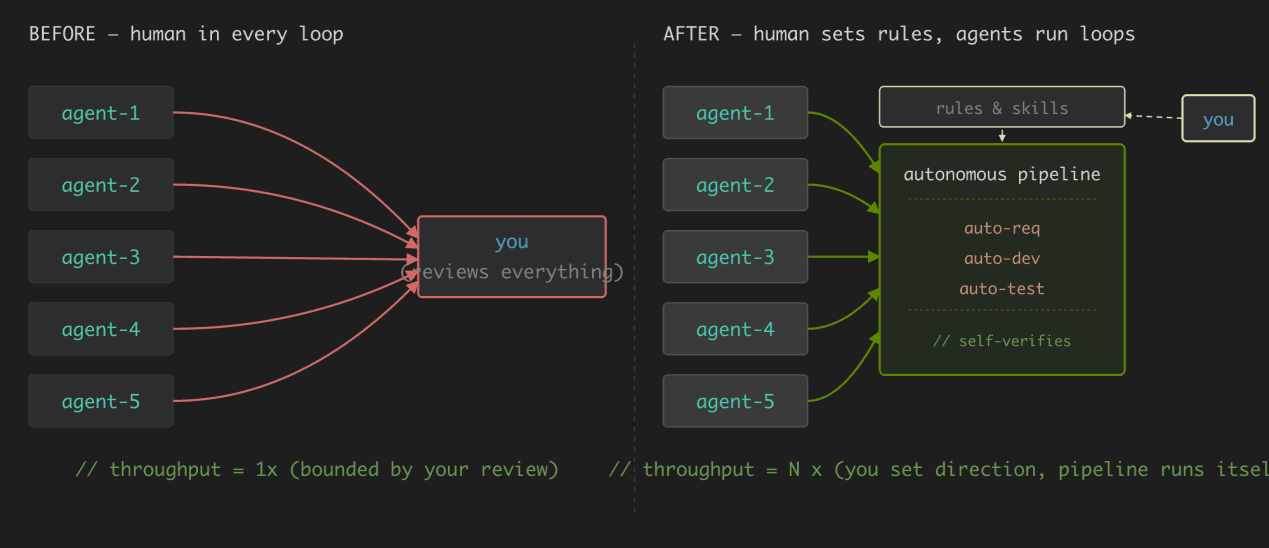
These three bottlenecks share a common feature: they all require a human-in-the-loop. And human attention is serial and limited. That's why in the past, even if you could launch five Agents simultaneously, efficiency wouldn't increase by five times—because you still had to review their outputs one by one, communicate requirements one by one, and control the architectural direction one by one.Parallel Agents ultimately get stuck at the human single-point bottleneck.
2025 and Before: Human is the Driver, AI is the Co-pilot
TL;DR: The common point of solutions before Opus 4.5 was "better collaboration between humans and AI" rather than "letting AI handle things on its own"—human is the driver, AI is the co-pilot, parallelism is meaningless, it just turns queuing into concurrent queuing.
Before the second half of 2025, the industry's solution to these three bottlenecks had a common theme: let humans and AI collaborate better, rather than letting AI finish things on its own—human is the driver, AI is the co-pilot (Copilot), parallel development had not yet arrived.
InRequirement DeliveryIn terms of aspects, there are two mainstream approaches. One is the Spec-based approach, which uses formal documents to describe requirements as precisely as possible before handing them over to the Agent for execution; the other is through multi-turn conversations, repeatedly negotiating with the Agent until it truly understands what you want. Both approaches require continuous human involvement.
Incorrectness assuranceaspects, it largely relies on manual code review. Humans review the code generated by the Agent section by section, identify logical flaws or boundary omissions, and then feed the review comments back to the Agent. After several rounds of revisions, usable code is finally produced.
Inmaintainability assuranceaspects, architecture design and code organization remain human-led work. You need to tell the Agent which module the code should go into, which design pattern to use, and which layering principles to follow; otherwise, the Agent will improvise on its own, producing code with a wide variety of structures.
At this stage, true "autopilot" has not yet arrived. Therefore, AI Coding products in this period mostly focus on optimizing the human-AI collaboration interface: helping you discuss requirements more efficiently (e.g., early CodeBuddy, various Spec-based programming tools), or making code review more convenient (e.g., IDE products like Cursor).
Parallel development doesn't make much sense at this stage—Even if you open five Agent windows, they're all waiting for you to review code, answer questions, and confirm solutions.
2025 H2: A Leap in Capabilities
TL;DR: In the second half of 2025, frontier models collectively leaped in four directions: debugging, instruction following, Skill rules, and Computer Use. For the first time, mechanisms can replace humans in addressing the three previous bottlenecks; at the same time, failure becomes cheaper, and "try multiple paths in parallel and pick the best" becomes a basic approach.
In the second half of 2025, frontier models made a significant collective leap in code ability, instruction following, and long-horizon task completion—exemplified by models like Opus 4.5, which for the first time allow mechanisms to replace deep human involvement in addressing the three previous bottlenecks. In other words, truly parallel development finally has the prerequisites.
This leap is specifically embodied in four directions:
Significant improvement in autonomous debugging. As long as the Agent is given a runnable debugging environment (terminal, logs, test framework), it can autonomously locate and fix most common bugs encountered in daily development. In the past, humans had to point out "there's an off-by-one error here"; now the Agent runs tests, reads error messages, and traverses several layers of the call stack by itself to resolve the issue.
"Understanding correctly" more easily translates into "implementing correctly." If the Agent has no deviation in understanding the requirements and is given a test environment and clear acceptance criteria, then the code it writes, after autonomous testing and fixing, can be basically guaranteed to be functionally correct in common business scenarios. Non-functional requirements (concurrency, performance, security) and architectural trade-offs remain exceptions, as discussed later.
Engineering norms can be partially internalized through Skills. Providing the Agent with structured Skill files containing software engineering practices—naming, layering, module boundaries, commit conventions, etc.—enables it to comply with thevast majority. Note it's "vast majority": many design principles inherently conflict with each other, and even senior engineers often struggle to judge them. The Agent will also make mistakes in such trade-offs. This point will be elaborated on later.
General Computer Use capability has greatly improved. The Agent is no longer limited to reading and writing code files. It can smoothly interact with the terminal, browse the web to look up documentation, operate GUIs to complete configuration tasks, and some have even used the Agent as an advanced shell. A direct consequence is that many software installation and environment configuration documents are becoming "for the Agent to read"—a Markdown file, and the Agent can automatically set up the environment.
These four changes combined mean:Humans can largely step back from the loop. It's not complete non-participation, but the mode of participation shifts from "line-by-line review" to "setting rules + accepting results + spot-checking key nodes." This opens the door to truly parallel development.
One additional hidden change: Failure becomes cheap
In addition to the four "capability" changes above, there is one moreAt the strategic levelthe change is worth discussing separately:The cost of having an Agent try a solution is much lower than that of having a human try one.
Before AI, you wouldn’t easily let an engineer "implement version A first, then version B" — human labor is too expensive to bear. So in the design phase, you had to think through all the trade-offs carefully; starting without clarity was a luxury. With Agents, this constraint has loosened —"Can’t figure it out? Then have several Agents each write one implementation, run tests, compare results, and then decide."
This seems like a mere quantitative change, but it actually triggers a qualitative shift in strategy — "try multiple paths in parallel and pick the best" has gone from a rare practice to a daily option. This principle runs through the various parallel modes later in this article: in many scenarios you parallelize not because tasks can be cleanly split, but becausetrying is cheaper than thinking it through. The "Mode 2" mentioned later, where "let Agents each write one implementation and merge the best ones," is a direct embodiment of this.
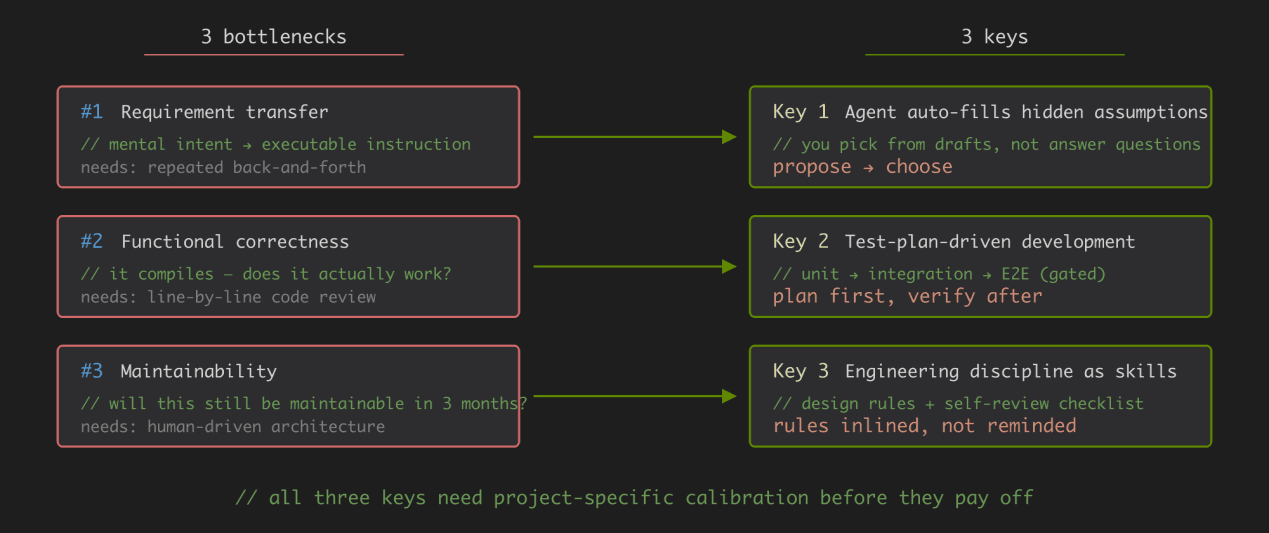
Three Keys to Reducing Human Involvement
Since the bottleneck lies in human involvement, the solution is to replace real-time human intervention with mechanisms. The following three sections correspond to the three bottlenecks and provide specific practices — together, they form the foundation for parallel development.
A word of caution:None of these three keys are "plug-and-play" — each requires you and the project Agent to iterate and calibrate together. What accumulates during this calibration process is more than just one thing — Skill files are the most explicit, capturing pitfalls, project conventions, and patterns where Agents tend to make mistakes; but there are also things that can only exist asintuition and feelthat stay with you: what types of tasks the Agent is reliable on, where you must keep an eye, and when its confidence should be discounted. These feelings are hard to express in documents, but they are decisive for how much you can let go. Before calibration is complete, you can't be optimistic; after calibration, you can truly let go.
Regarding tools: I have distilled my practices along these lines into a framework calledzero-review as a reference implementation. At the end of each key below, I will point to the corresponding skill; readers who need details can look there. But once again —This article is about the approach, not the framework; you can achieve the same effect with your own stack.
First Key: Requirement Alignment — Let the Agent Figure Out What You Want
TL;DR: Let the Agent identify the implicit assumptions in the requirements and produce several complete solutions sorted by priority for you to choose from — you shift from being the "answerer of questions" to the "reviewer of solutions."
Unclear requirements are the most common cause of rework in AI development. You think you've made it clear, the Agent thinks it understood, but the result is completely different from what you had in mind. To solve this, there are two complementary approaches.
Approach 1: Exhaustive Questioning — Let the Agent Proactively Expose Blind Spots
The specific operation is: first, describe what you want as clearly as possible in natural language, then switch to Plan mode (or equivalently, explicitly tell the Agent not to start coding) and make a request: "Before you do anything, tell me: what are your uncertainties about this requirement? List your questions."
The Agent will give you a set of questions. You answer them one by one, but do not let it start planning or coding — continue asking: "Based on my answers, are there any new uncertainties? Keep asking." It's like a requirements review meeting: you are the product manager, and the Agent is the developer continuously probing for details.
This process can last from 10 minutes to half an hour, depending on the complexity of the requirements. When the Agent's questions start to become trivial or repetitive, it means the core ambiguities have been covered. At that point, ask it to output a structured requirements document as the basis for subsequent development.
Approach 2: Solution Generation + Human Selection — Let the Agent Guess Your Intentions, You Just Pick
Exhaustive questioning, though thorough, is time-consuming and essentially still involves humans outputting information. The second approach is more efficient: let the Agent fill in the blanks in the requirements itself.
Here's how it works: You still start by providing a natural language requirements description, but this time you don't answer the Agent's questions. Instead, you give it a different instruction: "Analyze my requirements description, identify parts that are vague, undefined, or have multiple reasonable interpretations. Then for each such ambiguity, based on your world knowledge (if needed, search online for how similar products handle it), give the top 3 most reasonable solutions in your opinion, and explain why you recommend them."
For example: if you say "Create a user registration feature", the Agent will identify a series of issues you didn't mention but must decide—register with email or phone number? Is email verification needed? What are the password complexity requirements? What should the registration failure message look like? Then it will refer to mainstream product practices (e.g., "most SaaS products use email registration + email verification link") and give recommended solutions for each issue.
The core advantage of this approach is:You change from being the "answerer of questions" to the "reviewer of solutions". Reviewing solutions is much faster than answering questions—you just glance and say "OK, go with your recommendation" or "Change the third one to this." A large amount of requirement details are automatically filled by the Agent based on prior knowledge, with humans only making choices at key decision points.
The two approaches can be combined. For core requirements where you already have a clear idea, use approach 1 for thorough communication; for peripheral requirements where you don't care much about the specific implementation, use approach 2 to let the Agent make autonomous decisions. The final output is a complete requirements document covering all necessary details, which can be directly handed to the Agent for execution without repeated confirmation during development.
It should be particularly noted:Requirements alignment is the only step in the entire process that cannot be truly parallelized—it consumes your deep attention. This constraint will be mentioned again later when discussing parallel scheduling.
For specific practice, refer to zero-review/auto-req skill.
Second Key: Functional Correctness—Test Plan-Driven Development
TL;DR: Before development, write a complete test plan covering unit/integration/E2E; the test plan must be independently reviewed by another party (another Agent or you) to prevent the same Agent from contaminating both test and implementation. Write a separate Skill for non-functional requirements.
Humans no longer review code line by line, so who ensures the code is correct? The answer: testing. But not just a few arbitrary tests—instead, produce a complete test plan before development.
Here's how: Before the Agent writes any business code, have it output a test plan based on the requirements document. This test plan should cover three levels: unit tests, verifying the behavior of each function and module; integration tests, verifying that module collaboration meets expectations; end-to-end functional tests, simulating real user operation paths to verify the entire functional flow works.
These test cases represent "all conditions that a correct implementation must satisfy." They are determined before development begins and become the acceptance criteria during the Agent's development process. After the Agent completes code writing, it runs these tests on its own. If any test fails, the Agent automatically enters a debug-fix loop until all tests pass.
In this mode, you don't need to read every line of code written by the Agent. You only need to review whether the test plan itself is reasonable and covers key scenarios. The cognitive cost of reviewing a test plan is far lower than reviewing implementation code—because the test plan describes "what should happen," while the implementation code describes "how to do it specifically." As the requirements proposer, you naturally have judgment on the former, while the latter requires deep understanding of code details.
Prerequisite: Only when the Agent can act can testing be discussed
The Agent runs tests, debugs, and does end-to-end on its own—all of this is built on a frequently omitted prerequisite:It needs an environment where it can actually operate the system. Many teams give the Agent a docker with only source code, and then wonder why the Agent can't detect problems.
"Being able to operate" is not just "having a docker image that can run." You need to expose the corresponding operational capabilities to the Agent based on the application type:operational capabilities expose to the Agent together:
- Command line / API — shell + logs + testing framework, lowest threshold.
- Web Application — besides making the service run, you must exposebrowser use capability(Playwright service, headless Chrome with CDP endpoint, or VNC). Without this layer, the Agent cannot actually click buttons, cannot see page responses, and cannot perform real end-to-end testing.
- Desktop / GUI Application — must exposeGUI use capability(X11 forwarding, xdotool, screenshot pipeline). Otherwise the Agent can only "imagine" what user operations look like.
- Complex System(state machine, asynchronous, concurrent, long-running processes) — besides logs,must expose a debugger(gdb / DAP / Chrome DevTools Protocol / language's built-in debugger). Let it set breakpoints, inspect variables, view call stacks, instead of guessing by piling print statements in bash.
A simple self-check:Imagine a new engineer who can only use the tools you provided — can they reproduce a live bug? If they cannot, the Agent cannot either.
The capabilities given to the Agent must align with those given to the engineer. This is the foundation on which TPDD itself can stand — if the provisioning is insufficient, all the subsequent test plans, independent reviews, and role-playing are just empty talk.
Why the test plan must have an independent review
Here is a trap that is easy to overlook: if both the test plan and the implementation are given tothe same Agent to complete, then its understanding bias of the requirements will simultaneously contaminate both the tests and the code — the tests and code will both err, both pass with green lights, and you still think everything is OK.
This is the biggest logical flaw in the TPDD paradigm.The solution is: the test plan must go through an "independent" review before entering the implementation phase.
"Independent" has at least two ways to achieve it —
- Human review. You, as the requester of the requirements or a senior colleague, review from a business perspective. The advantage is that you bring domain knowledge and business judgment; the disadvantage is that it consumes your deep attention and cannot be parallelized.
- Review by another Agent. Start a brand new session of an Agent, give it only the requirements document and the test plan (not the implementation context), and let it find flaws. Essentially, it is multi-Agent cross-validation — the understanding bias of one Agent is unlikely to completely coincide with the bias of another fresh Agent, so it can catch a considerable portion of errors caused by "understanding bias". The advantages are low cost, parallelism, and no fatigue; the disadvantage is that its business perspective is still second-hand.
The two review methods are not mutually exclusive; they can be used in combination based on project complexity.:
- Low complexity, controllable risk projects(Internal tools, prototypes, exploratory experiments) — Just have another Agent review it; you glance at the conclusion to confirm the general direction hasn't gone astray.
- High complexity, high cost of mistakes projects(Critical online paths, finance-related, core modules with multi-person collaboration) — Agent first reviews to filter out obvious pitfalls, then you conduct a business perspective review, paying special attention to three blind spots: (a) Are all boundary conditions covered? (b) Are error paths and exception branches covered? (c) Does the test actually verify "what should happen" rather than "what already happened" (self-loop)?
In other words, the review step cannot be omitted, but the subject and depth of the review should match the project complexity.The most critical point is "independence" — the reviewer must not be the same Agent in the same session that writes the tests and implementation. As long as this rule is followed, contamination can most likely be blocked.
Scenarios not covered by functional tests: write dedicated Skills
Basic unit/integration/end-to-end tests address "functional correctness." But there are several types of requirements in a project that are not functional,the default test plan does not cover them:
- Non-functional requirements— concurrency race, performance bottlenecks, memory leaks, security boundaries.
- Behavior after long-term evolution— a piece of code passes all tests today, but after ten iterations over six months, it may fall apart.
The solution still follows the approach of the second key:Write the testing paradigms for these specific domains as dedicated Skill files and let the Agent execute them on its own. A few examples —
- Stress Testing Skill: tell the Agent how to construct high-concurrency load, how to observe p50/p99/p999, how to identify degradation curves, and what SLA breakpoints are. It can set up k6/locust/wrk environments on its own, run through preset stress levels, and generate reports with charts.
- Chaos Testing Skill: define which dependencies (database, downstream services, network) are subject to random fault injection; the Agent simulates kill, latency, packet loss, etc., according to rules, to verify system degradation and recovery.
- Security Testing Skill: automated detection logic for common vulnerability types (XSS, SQLi, privilege escalation, CSRF...). The Agent scans common attack surfaces like a junior penetration tester.
- Regression Evolution Testing Skill: run a periodic "architecture degradation self-check" on key modules in CI — whether files have become too large, whether single-function complexity exceeds thresholds, whether inter-module dependencies have formed cycles. This can catch some early signs of problems that only emerge after long-term evolution.
The design philosophy of these Skills is consistent with the earlier TestPlan:First, clearly describe in a structured way what "doing it right" looks like in this domain, then let the Agent execute independently. The process of writing a Skill itself is an opportunity to consolidate domain knowledge.
There is one more category that Skills cannot solve:
The "cannot see" of each role is the essence--Forcing the agent to see and report through that role's eyesUnder the novice role, the agent can only write "clicked save, page went white for 5 seconds"--it cannot write "initialization failed" because it simply cannot see the console. This ensures the feedback truly reflects what that type of user would report, not a second-hand translation from an engineer's perspective. Different roles expose completely different problems: novices expose obscure terminology and broken main flows, experienced users expose missing shortcuts, and adversarial users expose input validation vulnerabilities and abnormal crashes.
For specific practices, refer to the zero-review/auto-test skill.
Third key: Maintainability--Constraining Agent behavior with engineering discipline
TL;DR: Write the design principles of "good code" into the Skill file, so that the agent can check each item when coding and self-reviewing; leave the architectural trade-offs for you to spot-check.
Correctness is guaranteed by testing, but what about maintainability? By rules.
There is a set of time-tested core principles in software design (largely influenced by John Ousterhout's *A Philosophy of Software Design*), and they share one common goal:Control the growth of complexityIn the context of AI development, these principles can be encoded into Skill files and injected into the agent, giving it a basis for coding and self-review. The most critical ones are as follows:
Module depth. Good modules have simple external interfaces and deep internal functionality. Agents naturally tend to over-split--cutting classes very small and fine, creating a bunch of shallow modules. Clearly tell it: don't split for the sake of splitting; each module should hide enough complexity behind a concise API.
Information hiding. Modules should not share their internal implementation knowledge with each other. A common anti-pattern is to split modules chronologically ("do A first, then B, so split into two"), which almost inevitably leads to information leakage--the basis for splitting should be "who owns this knowledge", not the execution order.
Abstraction layering. Each layer should provide a different mental model. If a layer merely forwards calls unchanged to the next layer, it has no reason to exist. More importantly, complexity should be pushed downward--lower-level modules proactively take on more processing, keeping upper-level code simple.
Cohesion and separation. Code that must be understood together to make sense should be together; mixing general logic with special-case logic in a way that makes both hard to understand should be separated. Avoid producing coupled code where "the current function cannot be understood without reading another function entirely".
Error handling. The proliferation of exceptions is a hidden killer of complexity. Good design tries to "define away errors"--by adjusting semantics or designing default behaviors to reduce places where exceptions need to be handled, rather than sprinkling try-catch everywhere.
Naming and obviousness. Code should allow readers to correctly guess what it does at first glance. Naming must be precise, consistent throughout the codebase, and should not violate the reader's intuition--any developer new to the project should not be "surprised" when reading the code.
Documentation and comments. Comments should describe what the code itself cannot express--design intent, why a particular solution was chosen, the abstract semantics of an interface. Repeating what the code already says is redundant; missing what the code cannot say is lacking; both are bad comments.
Strategic design. Every modification should be an investment in the overall design, not a tactical quick patch. Resist the temptation to "just make it work first"--time saved by shortcuts will eventually be paid back exponentially in complexity. At the same time, be wary of over-design: solve the problem at hand; do not build unused abstractions for hypothetical future needs.
A fact that must be acknowledged: these principles themselves pull against each other.
The above eight principles are not a checklist that can be mechanically applied. There is inherent tension among them:
- Deep ModuleSays 'deep functionality, simple interface';Small and ComposableSays 'a module does only one thing.' These two often conflict on 'how large a class should be.'
- Strategic DesignSays 'invest a bit more this time for the future';Beware of Over-DesignSays 'don't build abstractions for hypothetical requirements.' There is no standard answer for the boundary between these two.
- Information HidingSays 'don't leak internals'; but excessive hiding can lead toShallow Module(the interface doesn't reveal what it can do).
Even experienced human engineers can repeatedly make wrong judgments on these trade-offs — relying on an Agent to consistently get it right with just a Skill file is not yet supported by evidence.The reality is: An Agent can get it right in most routine cases; the remaining part still requires you to spot-check, especially architecture-level decisions and long-term maintenance choices.
Which areas are most error-prone and which principles are especially important in your project — these are things that gradually settle into the Skill file through iteration. For example: if you find the Agent repeatedly chooses excessive decomposition in a certain type of scenario (e.g., creating five classes for a small feature every time), then write this counterexample into the Skill — 'In this project, don't decompose X-type scenarios into more than N classes.'The Skill library grows with the project; this is a continuous investment, not a one-time effort.
Three Phases of Actual Operation
After the Agent receives the requirements document and test plan, it first performs code structure and architectural design based on the above principles (module division, interface definition, abstraction levels, file organization); then it executes development and testing; finally, it conducts a round of self-review and adjustment against these principles, checking for shallow modules, information leakage, intermediate layers that only forward without doing work, naming inconsistencies, and other issues, and corrects them on its own.
What you need to do is to write these design principles into a Skill file, load it when the Agent starts; and after the Agent's self-review results are out, perform a spot-check on architectural decisions. As the iteration deepens, the number of spot-checks will decrease.
For specific practice, refer to zero-review/auto-dev skill.
Scheduling Techniques for Parallel Development
TL;DR: Three stable patterns from coarse to fine — cross-project / same repo different directions (git worktree isolation) / same task different concerns; plus an experimental cutting-edge 'Agent splits tasks and runs in parallel'. They are not mutually exclusive and can be nested.
The three keys solve the question 'can we let go of a single Agent'; in this section, we can finally talk abouthow to let go of multiple Agents at the same time.
Depending on the granularity of parallelism, there are three modes that can be stably used today (and a fourth mode currently in the experimental stage, discussed separately later).

Mode 1: Cross-project Parallelism – Different repos, different Agents
Coarsest granularity, most worry-free parallelism. Several independent projects at hand, each starts an Agent to drive its own development tasks. There are no code dependencies between projects, and no coordination needed between Agents. You just need to align requirements for each project separately, then let them execute independently.
This mode has almost no additional management overhead. The only thing to watch is to allocate your attention wisely – rotate among projects during the requirements alignment phase, rather than doing them one after another in sequence. A practical rhythm: give requirements to Project A's Agent and let it generate a test plan; in that gap, switch to Project B for requirements alignment; once Project B's Agent starts working, come back to review Project A's test plan. Like a tech lead shuttling between multiple meeting rooms.
Mode 2: Same project, different directions – Isolate parallelism with git worktree
In the same project, push several non-overlapping directions simultaneously, or have multiple Agents run the same requirement with different approaches and then merge the best – the former is 'doing different things separately', the latter is a direct application of the earlier point 'making failure cheap'.
Technically, git worktree is recommended for isolation. It allows you to create multiple independent working directories from the same repo, each checking out a different branch – Agents work without interference, and after completion, they merge back to the main branch in order of priority. Merge conflicts can be resolved with Agent assistance.
The key consideration for this mode: choose directions with low code coupling between parallel tasks. If two tasks heavily modify the same set of files, the cost of merge conflicts will eat up the time saved by parallelism. A simple rule of thumb: overlap of modified files <20% is fine for parallelism; >50% suggests serializing or re-splitting the task.
Mode 3: Same work item, different transaction types – Cross parallelism
Within the same feature, split work by transaction type and parallelize. Even the development of the same feature includes various transaction types of different natures (backend logic tests, UI tests, known bug fixes…), which can often be performed in parallel.
For a concrete example, suppose you are developing an 'Order Export' feature. You can launch three Agents simultaneously: the first Agent handles backend logic tests – constructing a backend test plan covering various edge cases (empty orders, large data volumes, concurrent exports, etc.), writing test cases and executing them. The second Agent handles UI-level tests – building end-to-end UI tests with Playwright, verifying the export button interaction flow, file download behavior, error state display, etc. The third Agent fixes several known bugs you've observed during earlier development.
These three transaction types are different (backend tests, UI tests, bug fixes), involving different code areas and toolchains, making them naturally suitable for parallelism.
Mode 4 (Frontier experiment): Parallelism within a single task – decomposed and scheduled by the Agent itself
This mode is currently in early exploration and its behavior is not yet stable – it is presented here to set your expectations, not as a recommendation to rely on it today.
In the first three modes, you decide the granularity of parallelism; Mode 4 delegates control to the Agent itself:Throw a task at it, and the Agent itself identifies which submodules can be developed in parallel, and splits them into multiple concurrent streams. For example, Claude Code's team feature already shows the prototype – you don't need to manually open worktrees or assign tasks; the Agent handles scheduling itself. But current limitations are real: context sharing across sub-Agents is still fragile, collisions occur when boundaries are unclear, and manual intervention is still needed during the merge phase.
However, the prerequisites for making this mode work can be built starting today –Module boundaries, interface contracts, and data flow must be clearly defined before development. If several sub-Agents have to repeatedly align interfaces during coding, they will quickly collide, making the merge worse than serial development. This is precisely the direct payoff of the third key: projects with a solid architecture phase naturally have the potential for Agent-driven autonomous parallelism; conversely, if the architecture phase is neglected, even if the underlying system supports team mode, you won't enjoy this benefit.
zero-review/auto-dev The architecture design phase of zero-review/auto-dev has already enforced 'modularity + interface contracts' as a hard requirement, precisely so that downstream can immediately use it once this capability stabilizes.
In practice, the first three modes are not mutually exclusive – you can embed Mode 3 within Mode 2's worktree framework, or use Mode 1 for cross-project coordination in large organizations. The finer the granularity, the higher the demand on your attention switching ability, but the greater the benefit.
New bottleneck from parallelism: AI output you can't digest in time
TL;DR: This is not a future bottleneck – you will hit it as soon as you launch the 3rd Agent. Output (code, test reports, feedback) piles up on you, and it needs to be digested by Agents; this closed loop is not yet running.
Suppose you have launched several parallel Agents as described, each producing code, test reports, user test feedback, and retrospective summaries. In the first week, you'll feel the rhythm is great. In the second week, you'll find that – most of your day is spent reading various reports from the Agents, and you realize many of them are actually redundant or low-priority trivial issues pushed to you. You've gone from 'code reviewing' to 'report reading', and the bottleneck has quietly returned to you.
The imagined solution is the same as the earlier bottleneck-breaking approach –Output also needs to be digested by the Agent: Read in batches to find patterns and duplicates, merge different descriptions of the same thing, assign to the next development round by type, prioritize based on 'how many users affected × is there a temporary workaround', attach a reason for each, only escalate high-priority items that truly need your decision. Once this is in place, the entire chain becomes a closed loop: you issue requirements → Agent performs parallel development → output is automatically digested and organized by the Agent → new work items are sent back to the Agent.
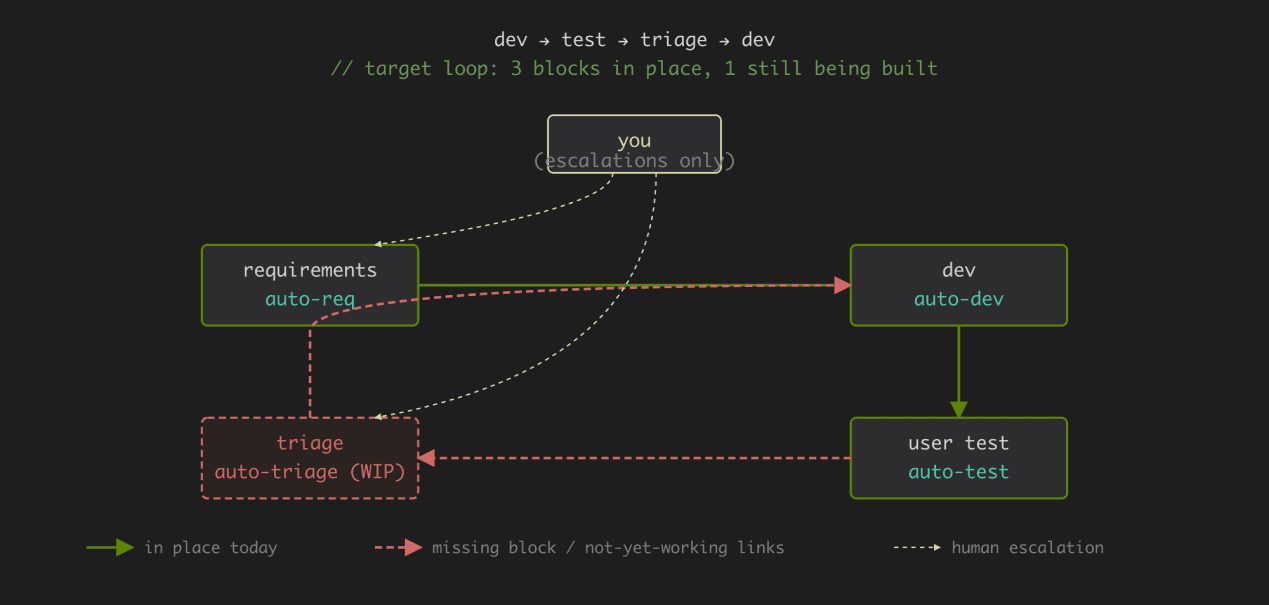
But this closed loop is not yet operational. I am at zero-review left a spot for this line in (auto-triage skill), but to be honest, today it cannot reliably replace humans in this task—classification easily loses focus, merging easily misses truly independent issues, priority judgment lacks business perspective. This is the part of the entire collaboration chain that I find most unreliable and most worth continuing to invest in.
Before this closed loop is operational, what you can do is establish some transitional buffers: enforce a structured 'summary + severity + suggested action' template for each Agent's output, so that you only need a quick glance each day to make priority decisions; write frequent low-priority issues into the Skill so the Agent ignores them automatically; set a fixed time block for 'reading output daily' and don't let it fragment your entire workday. But these are just buffers—the real solution is to complete the fourth building block of the entire closed loop, and that day has not yet come.
Some practical advice
Start with two Agents, gradually increase. If you don't have experience with parallel development, don't start with five or six Agents right away. First try managing two simultaneously, get familiar with the rhythm, then gradually increase.The comfort upper limit for beginners is usually 3–4 Agents—any more than that, just switching context and reviewing test plans will become a new bottleneck. To break through this limit, it's not willpower that truly matters, butmore mature task decomposition techniques: cut a large task into sufficiently independent pieces in advance, so that each Agent's output doesn't require frequent interruptions from you, and raise the granularity of review from 'each output' to 'a batch of outputs'. This technique grows gradually through practice—once you are skilled, running 6–8 Agents simultaneously is possible.
Requirement alignment cannot be parallelized. This is a counterintuitive but important point. Although development execution can be parallelized, the requirement alignment phase requires your deep thinking, which is hard to truly parallelize. The recommended approach is: complete requirement alignment for each task serially (10-30 minutes each), then start development execution in parallel. Think of requirement alignment as 'loading bullets' and development execution as 'shooting'—loading requires focus, shooting can be simultaneous.
Build a project-specific Skill library and load it continuously. Engineering standards, architectural principles, testing requirements, team preferences—write them into one Skill, uniformly loaded when each Agent starts, to ensure consistent output style and quality standards. Previous sections have repeatedly discussed how this library grows through practice; here just one reminder:For the output of parallel Agents to be seamlessly merged, the prerequisite is that they receive the same set of specifications. Otherwise, three Agents will produce three different styles, and merging them will be like a patchwork quilt.
Link 'review granularity' with 'project complexity'. Low-complexity projects (internal tools, prototypes)—let it go, just glance at the output and test plan; high-complexity projects (critical online paths, systems with security/performance requirements)—review test plans line by line, spot-check architecture decisions, and for key modules, it's still worth having a human read the code. This is not about being 'lazy' or 'diligent', but about directing limited attention to where it is truly needed.
But this won't make you feel more relaxed
TL;DR: Output is amplified, but your mental consumption per unit time is also amplified—the arithmetic is favorable, but it's not free; you have to proactively create some slack.After all the good talk, I must add an honest note: this path will not make things easier; in fact, it will probably be more tiring. Output is amplified, but the mental effort you expend is also amplified—and with almost no slack.
Coding has a rhythm—write a few lines, run it, change a bit, run again—hands and brain alternate, and when stuck, you can semi-automatically try for a while. After switching to parallel scheduling mode, you spend all day making judgments: accept this requirements document? Which option? Which priority? What is seen in this retrospective? One Agent decides direction every few minutes, five Agents producing simultaneously means five judgments piled in front of you. The time may not be longer, but
The time may not be longer, butMental expenditure per unit of time increases significantly。
In other words, you've gone from "physical plus mental" to "pure mental". The math is favorable — output magnifies several times — but total mental investment hasn't decreased, it's even higher.
So you must actively create gaps: read status reports in batches, don't let Agent outputs fragment your attention like chat messages; set aside uninterrupted time to think about direction and process; don't mistake "letting go" for the illusion that "I don't have to do anything". What AI saves is your hands-on work; the saved time doesn't automatically become leisure — you have to actively give it space.
You are no longer the person typing on the keyboard; you arethe person who designs and runs this entire collaborative system. Your position is higher, the leverage is greater, and the demands on judgment are also higher. Tiring as it is — but this kind of fatigue is the kind that truly creates value.
Summary
The essence of parallel development is not "running more Agents simultaneously", but "reducing the number of times each Agent requires human intervention". Only when each Agent can independently complete high-quality work with minimal human oversight does parallelism become meaningful.
Behind this are three keys: replace repeated communication with structured requirement alignment processes (remove requirement transmission bottlenecks), replace line-by-line code review with test-plan-driven development (remove correctness bottlenecks), replace manual architecture oversight with engineering discipline from Skill injection (remove maintainability bottlenecks). Add one more strategic change: once failure becomes cheap, "try multiple paths in parallel, merge the best" becomes the basic approach.
Once these three conditions are fully refined, your role shifts from "pair programmer for each Agent" to "technical lead for multiple Agents" — you are responsible for setting direction, defining standards, reviewing test plans, and doing spot checks at key nodes; the actual coding, testing, debugging, and most architectural details are completed autonomously by the Agents.
And this dividend is not limited to development — any mental labor that can be decomposed into independent subtasks is equally applicable to this approach. Writing code is just the first scenario that works.